案例企业有着强大的粉丝团体,一直走的是粉丝经济,虽然在向品牌经济过渡,但粉丝经济还是营收的重要构成。为了最大化粉丝收益,案例企业就不断推出新品,基本上是每周都有新品上市。该企业走的是中高端、差异化路线,快时尚,品种多,批量小,首批推出一般也就几百到几千件。多种少量让预测更难做,要么过剩,要么短缺,在案例企业得到充分体现。
这不,有一款新品在4月份推出,几天就卖完了三四千件,紧赶慢赶地返单,等第二批到货时,都已经6月份了,爆款带来的"热气"也快消散完了。有爆款,自然就有滞销。比如有个产品,为了走量降成本,首批进货几千件,结果只卖掉几百件,投入巨大的资源促销也不管用,一旦过季,就只能等到第二年,呆滞风险就很高。
需求不确定性很大,首批订货风险大,需求预测的压力就很大。预测风险高,没人愿意承担,最终就只能是老板拍板。
老板做预测,自然有老板做预测的原因:他是最有经验、最有权威的那个人,而且最能承担预测失败的后果。但是,随着业务连续翻番,新产品越来越多,事情越来越多,老板越来越忙,离消费者和一线运营越来越远,能花在需求预测上的时间越来越少,很多时候就只能拍脑袋做预测,其弊端也就越来越明显。"希望大boss理解科学的办法和拍脑袋的差别,特别是一个或者是二个人的拍脑袋",案例企业的一位同事如是说。
老板当然理解科学决策和拍脑袋的差别。天底下没有一个老板会说,科学决策很糟糕,让我来拍脑袋。但问题是,当我们缺乏有效的机制,没法有效整合跨职能的智慧和信息,一帮人没法有效决策的时候,老板不靠自己拍脑袋,还能靠什么?所以,这里的问题不是改变老板的行为,而是找到更好的方法论来整理数据,整合跨职能的判断,做出更准确的预测来。当集体的决策能力提高了,老板自然就不用拍脑袋了。
这方法论就是德尔菲专家判断法。当数据非常有限,未知因素非常多,决策的不确定性非常高的时候,德尔菲法是一种相当不错的选择。
新品预测试点项目准备
对于案例企业,我们确定一个具体的产品来做试点,以导入德尔菲专家判断法。该产品正好处于开发后期,需要确定首批订货量。该产品也是案例企业重点开发对象,能够得到专家们(跨职能团队)的重视。
找好了产品,我们围绕这个产品,进一步确定了该新品预测的的专家团队,包括以下岗位:
- 产品经理。该企业采取集成产品开发(IPD),由产品经理担任项目经理,对产品全权负责,在新品上市中扮演关键角色,包括新品的需求预测。
- 设计师。该职位具体负责该产品的设计,熟悉产品的定位,比如是基础款,还是大众款,以及特定设计对需求的影响,比如颜色、辅料的选择等。
- 店铺经理。该职位负责主要网店的销售,熟悉消费者的需求模式,有能力对不同产品做出横向比较,也熟悉上新促销计划等。
- 数据工程师。实际上的计划经理。该职位负责数据化,熟悉各种产品的需求历史,能从历史数据的基础上帮助需求预测。
- 研发负责人。研发负责人特别熟悉产品,了解用户。她在微信群、QQ等社区小组里非常活跃,熟悉用户需求,对用户认知挺多。
- 销售负责人。虽然直接参加新产品开发较少,但经验丰富,熟悉客服团队的反馈,能帮助做多个产品的横向比较。
- 供应链负责人。熟悉产品的成本、最小起订量、供应商的阶梯报价等。也熟悉关键原材料的共用性和货期,能够从供应端帮助需求预测。
- 总经理。创始人不可替代,尤其在还处于小而美但快速发展阶段的案例企业。总经理深度介入产品开发、企业运营、定价决策等,经验丰富,历来在新品的需求预测上扮演关键角色。
确定了产品和专家团队后,组织者把专家团队召集到一起,培训德尔菲专家判断法,展示产品的样品,启动专家团队"从数据开始,由判断结束"的新品预测流程。
首先,我们究竟要专家团队预测什么?在一个微信群看到这幅漫画,医生们在上街罢工游行,但举起的牌子上,却歪歪扭扭地写着处方一样的字,谁也看不清楚他们的诉求是什么(如图 1)。你知道,这是在戏谑那些开处方如同天书的医生们。放在新品导入的专家决策中,我们究竟要这些专家预测什么?案例企业说,产品上新,不就是要预测首批订单量,也就是说,首批向供应商的进货量呗。这不清楚,有两个问题:

图 1:诉求不清,是另一种的垃圾进,垃圾出
其一,预测有数量和时间两个维度,两者缺一不可。首批订单量只有数量,没有时间----这首批制造的产品,究竟预计在多少时间售完?如果我们把时间的口子开着,每个专家成员就得做出自己的假定;对时间的假定不同,专家成员的预测肯定不同;缺乏一致性,就没有可比性,专家判断就成了垃圾进,垃圾出。
其二,"首批订单量"问的是供应,即给供应商下多少订单。虽说供应主要是由需求决定,但两者并不是一回事。作为供应,首批订单究竟生产多少,还受产能、采购周期、规模效益等影响。比如最小起订量越高,首批订单量可能越大;补货周期越长,订单量就越大;产能有限,可能得降低订单量。专家团队中,大部分人最熟悉的是需求,没法针对供应做出很好的判断。
跟案例企业讨论以后,我们决定问专家团队两个问题:(1)上新30天内,您认为可能销售多少?( 2)除此之外,您认为还可备多少产品的原材料(长周期物料),这样一旦需要补单的话,我们可以快速反单?我们特别提醒,希望这些原材料备货能在3到6个月内消耗完毕,以期控制原材料的呆滞风险(这也是给专家团队界定预测的"时间"维度)。
问题1其实问的是上新30天的需求预测,有时间、有数量,限定地很清楚。在上新阶段,专家团队里的销售、设计、产品管理等职能深度介入,对过去的新品有一定的经验,对下一个新品能够做出一定的预判。
问题2的目的是确定第二、第三个月的预测。案例公司的整个供应链周期大致是3个月:原材料采购1个月,加工成半成品1个月,加工成成品1个月。由于上新的不确定性非常高,案例企业通常采取长周期原材料统一采购,以获取一定的规模效益,但只把部分加工成半成品、成品,以控制成品的库存风险。上新一开始,第一天的销量就很有参考价值,决定是否要赶快把剩余的材料加工成半成品或者成品(这点后文还会讲到)。
我们理解,第一个问题相对更直观,应该能得到不错的判断;第二个问题相对更难做判断,专家团队需要更好地理解整个供应周期,以期提高对长周期物料的预测、管理(在具体案例中发现,专家们对第二个问题判断的确不是很好)。
确定了要问的具体问题,下一步是确定哪些信息是已知的,可以统一提供给专家团队,以缩短学习曲线和提高决策质量?要知道,专家决策并不是拍脑袋;他们是在以往经验的基础上做判断。而以往的经验呢,其实很多已经凝聚在数据里,比如销量,我们可以汇总这样的数据,统一给专家团队。这对那些不经常跟数据打交道的职能,比如设计和产品管理,特别有帮助。否则,他们就会纯粹拍脑袋。即便那些跟数据打交道的人,也可能嫌麻烦,不会去找历史数据而拍脑袋了事。
在案例中,我们决定提供两类的信息:(1)类似产品的信息,比如不同时段的销量;(2)该产品的特定信息,比如产品的定位,原材料的最小起订量,供应商的阶梯报价等,如图 2。
类似产品信息:去年有6个类似产品,分别是什么时候上市(这影响季节性产品的销量),首批生产了多少,上架30天卖掉多少,首月售罄率是多少,3个月、6个月累计卖掉多少,是不是断码过(断码的话表明销量比实际要低),这让专家团队有了更多的横向比较的信息。组织者原来还提供前年的类似产品,但有两个问题:(1)时间较久了,上新期间的销售数据不全;(2)两年的产品太多了,容易造成信息过载,反倒影响专家成员的有效判断。组织者也想提供每个产品的四象限分类(产量的高低与销量的高低),以及退货率等,同样有信息过载的问题,就一并拿掉。

图 2:可参照产品的历史销量(案例企业的机密信息遮盖掉了)
该产品的信息:产品定位是高价位、中价位还是基础款(走量的)?跟已有产品的关系是互补,蚕食,还是独立?这些都会影响产品的需求。此外,我们还提供了采购相关的数据,比如主要材料的最小起订量,供应商的阶梯报价,有无特殊工艺,比如染色、表面处理等,以及相应的附加费用(跟最低起订量有关)。
项目结束后反思,采购相关的信息,比如供应商的阶梯报价、主要材料的最小起订量等,对于需求预测其实并不相干----这些因素会影响供应,但不会影响需求(当然你也可以说,这影响成本,成本影响价格,价格影响需求。但是,这么复杂的关系,有几个专家能够量化?)。给专家团队太多的信息,反倒容易引起混淆----比如这里的最小起订量3000,就在后面多次出现,成了好几个专家的"预测"。
组织者把关键的背景信息准备好,编辑成一页A4纸文件,就召集专家会议,再一次介绍了德尔菲专家判断法的方法论,展示了产品样品,把基本的背景信息分发给大家,开始新品的转件判断法。
第一轮,每一位专家回到自己的办公间,分析已有的数据,搜集更多的信息,独立、背靠背地做出判断,扫描二维码,通过问卷星(www.wjx.com)在线填写以下信息:
(1)新品预测:上新30天内,销量预测是多少?还应该备多少原材料的库存;(2)所依据的理由;(3)进一步完善该方法论的建议,比如还需要提供哪些有用的信息,邀请哪些合适的人加入到专家团队等。
在问卷最后,我们要求每位专家填写自己的姓名等信息。这一方面为督促专家们认真完成任务,另一方面也帮助组织者跟踪各个专家的判断结果,以期循环改进。在这里,组织者明确说明,填写的结果会以匿名的方式反馈给专家团队,以便让专家们没有后顾之忧,做出最好的判断。
组织者汇总第一轮的结果,比如8个跨职能专家中,每个人做的预测分别是多少,其理由是什么,统一分发给专家团队。召集专家团队开个简单的会议,确保大家理解第一轮的结果。注意:会议不是让大家判断谁对谁错,应该怎么办。否则,强势职能可能影响弱势职能,强势人物可能影响弱势人物,从而影响了第二轮预测的客观性。
第二轮的方法论与第一轮一样,由每个专家成员独立、背靠背地决定,是否修改自己在上一轮的预测结果,并写明理由----任何人都可以填写一个数字,真正重要的是数字背后的原因。
组织者汇总第二轮的结果。如果第二轮的结果分歧还比较大,就进入第三轮。希望最多三轮,专家团队在该新品的预测上,能够达成相当的共识,组织者最终以取平均值的方法,决定该产品的新品预测(结果两轮就结束了)。
专家判断的结果分析
对于上新30天的销量预测,两轮预测后,7位专家的结果明显趋同(原来有8位专家,其中一位专家度假,只做了第一轮,就剔除了)。表现在标准差和离散度上,就是这两个数值明显降低----离散系数从第一轮的0.75降为0.22,标准差从837降为182,如图 3所示。
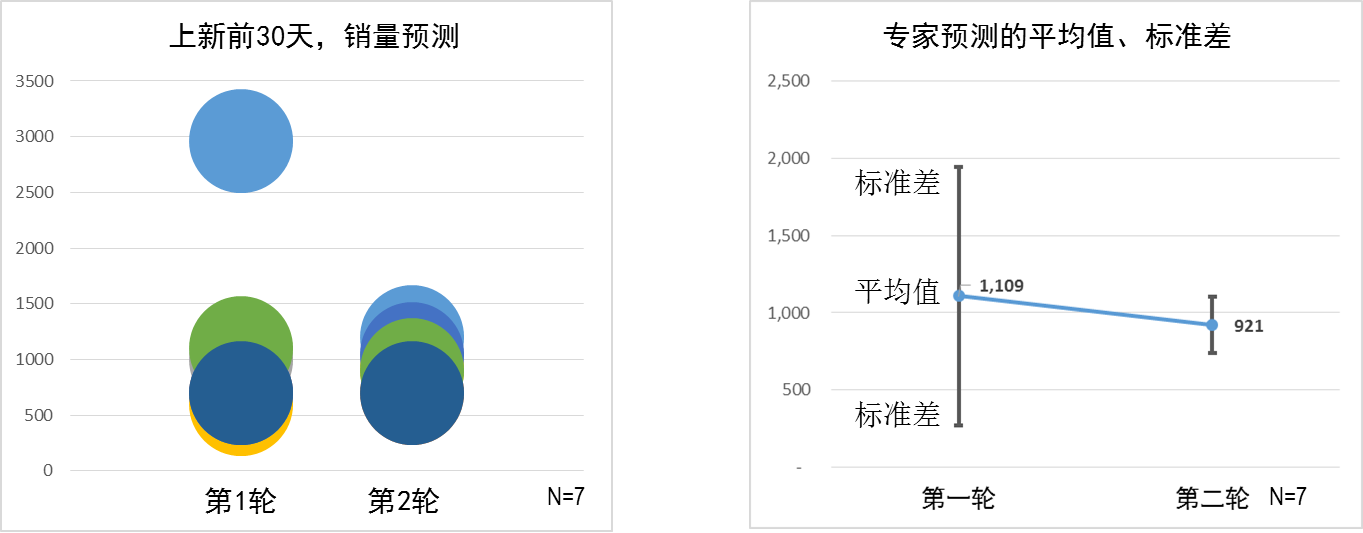
图 3:两轮预测后,专家预测值的离散系数大幅下降,预测值更加趋同
但是,对于额外备料的预测,两轮专家判断后,预测的离散度却依旧很大。
如图 4,虽然左边的图片看上去更加"趋同"了,但这有误导:第一轮的预测是从0到3000的很多值,第二轮则主要集中在1000和3000上----3位专家预测1000,另3位预测3000(还记得3000是什么吗?主要原材料的最小起订量!)。
这不应该是巧合,看上去更像相当一部分人心里没底,就"扎堆",看第一轮预测中哪个人的理由充分,就随那个人了:首轮预测3000的那位说,基于成本和此产品的差异化设计,该产品的目标应该是基础款、高销量(注意,3000就是图 2中主要原材料的最小起订量);而首轮预测1000的那位则说,该款式设计上与别的"撞色","在夏天不讨喜,预计只能在春秋两季去推",而且3到5月有多款类似产品上线----该款明显是低销量,没后劲。这两个理由看上去都很充分,大家就跟风变成了两派。不过1000跟3000的差距可太大了,所以说专家们在这个问题上并没有达成一致。
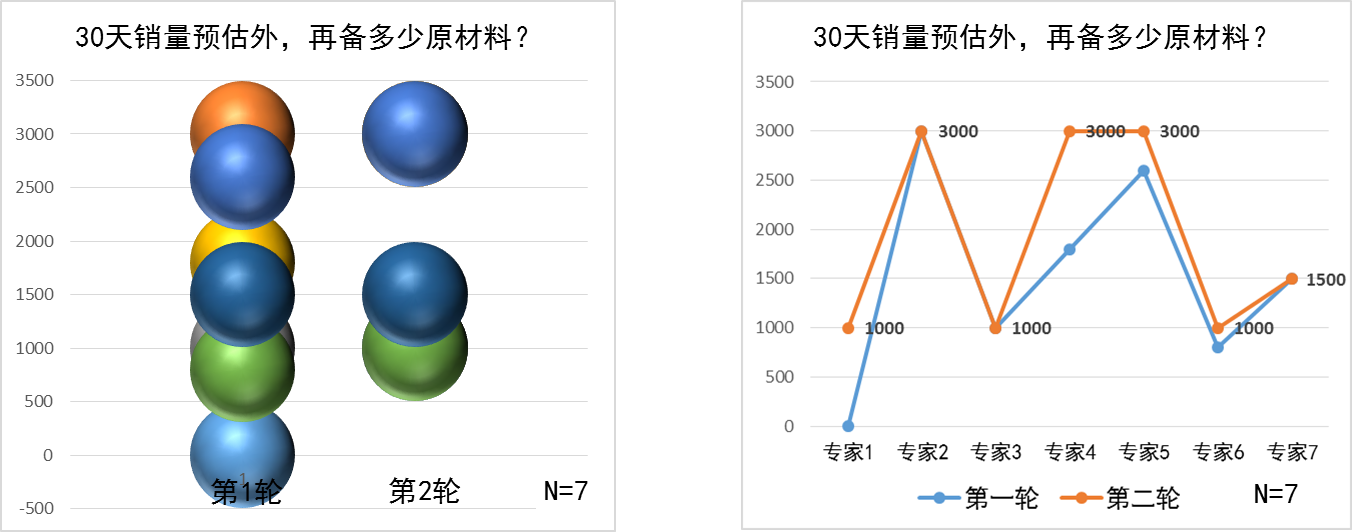
图 4:两轮预测后,额外备料的预测还是差异很大
当然,这也反映了在该产品的定位上,案例企业还没有达成共识。在预测反馈中,好几位专家也提出这点。这是产品开发的任务,产品经理在开发初就该清晰定位。
作为案例设计者,我认为我们问了错误的问题:对于专家成员中的产品经理、设计师、研发负责人等,他们的主要经验在上新前后----那个阶段的产品他们最关注;至于上新结束后,补单该补多少,他们一不在乎,二没经验,自然就做不出高质量的判断。
我的建议呢,就是以后不让专家组预测后续备料,而直接由供应链根据30天销量的预测,来预估后续两个月的需求----我们后面会讲到,上新期间的需求和后续正常销量关联度很高,可以相当靠谱地推导出后者。
30天很快过去了,实际销量出来了,该产品卖掉858个。如果与第二轮预测的简单平均值921个相比,误差为7%;如果把第二轮预测剔除最大值、最小值后取平均,误差为6%,如图 5。不管用哪种统计方法,预测准确度是非常高的,远超我们的期望。
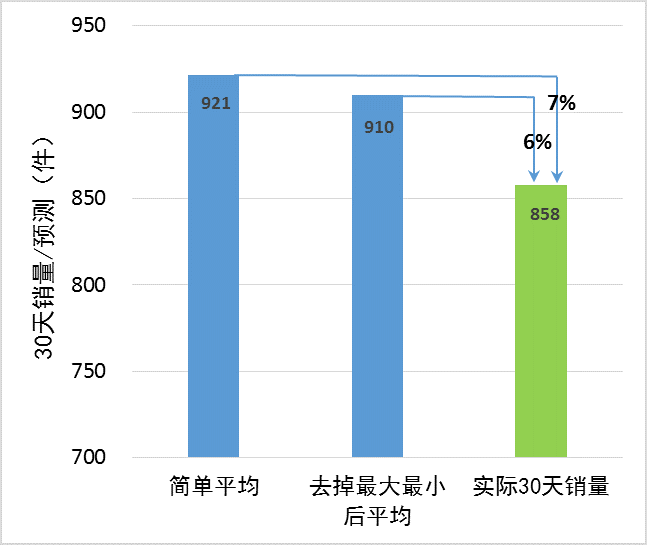
图 5:上新30天,专家团队预测的准确度分析
老总也参加了专家团队,原先就是由他拍脑袋做预测的。让我们看看老总的预测准确度如何。图6总结了他个人的30天销量预测:第一轮预测为700,比实际低18%;第二轮修正后为1050,比实际高22%。对于新品来说,这样的预测准确度是相当高的----老总受过很多苦,吃过很多亏,交过很多学费,还是有很多经验的。不过问题是企业越来越大,产品越来越多,他分身乏术,对付不了这么多产品。但是,两轮的准确度还是明显不如专家判断法。看来,专家团队一出手,就"小赢"老总一把,可谓旗开得胜。

图6:上新30天,老总的两轮预测准确度
老总的预测第一轮偏低,第二轮就偏高,看样子也是受了专家团队的影响(老总是专家团队成员,看到了专家团队的首轮预测结果)。专家组的两轮预测调整幅度都不超过10%,而老总的调整幅度则高达40%。从第一轮的显著偏低,到第二轮的显著偏高,表明作为长期的兼职预测者,老总本身也没有一套科学的方法论:他的第一轮预测比较保守,因为花的是他的钱,估计被以前的过剩整怕了;一旦发现别人的预测都较高,老板也就随大流,相信真理是掌握在大多数人手中,于是就拔高自己的预测。
《超预测:预测未来的艺术和科学》一书说道,在预测准确度上,一个人要打败多个人,需要有很强的能力和相当的训练;一群人要打败一个人,则不需要多少专业知识和训练[1]。这放在这个案例中也适用:没多少训练的专家团队,相当容易地打败了吃过很多苦、试过很多错的老总。
综合两轮预测,我们发现,对于多位专家的预测,如果拿掉最高值、拿掉最低值,预测的准确度就相对更高。这估计是因为刚开始应用德尔菲法,有些成员还不熟悉这一方法论,也不熟悉需求预测本身。比如新的产品经理以前主要负责设计,不参与预测,对需求预测本身不熟悉。反映在其个人预测准确度上,两个产品都是7人中的最低。掐头去尾,剔除两个极端值,有助于提高预测准确度。
另外,如果有些成员在部门利益驱动下,比如销售希望不断货,采购希望能满足最小起订量等,有意虚高或者虚低(这些都可以在事后总结时发现),我们也要考虑剔除最大、最小值。但是,在专家团队比较小的情况下,这样做会导致样本更小,降低了数理统计的可靠性。所以,当大家都熟悉了德尔菲法,也熟悉了需求预测,可以考虑采用简单的平均法。





评论