时间序列可以分解为三种成分:水平部分(平均值),趋势部分(上升或下降),季节性部分(周期性的重复),剩余的就是随机变动,即前三者都没法解释的"杂音"。我们常见的时间序列,根据复杂度的不同,一般上述三种成分中的一种、两种或三种组合而成。当然,你也可以把水平部分当成趋势的特例,或者趋势的一部分。那么,时间序列就可简化为两部分:趋势和季节性,以及两者之外的随机变动。下面这个例子就是这样分解的[1]。
图 1是5年期间(60个月),国际航班的每月乘客总数,单位是千人。最上面的是实际乘客数,你能看到整体乘飞机的人数在上升,你也能看到有一定的季节性变化。我们进一步分解实际值,发现乘飞机的人是一年比一年多,呈现明显的趋势,这就是趋势部分;季节性也很明显(这也符合常识:众多的节日在后半年,相应地乘客也更多);剩余的是随机成分,也就是难以系统地预测的部分[2]。
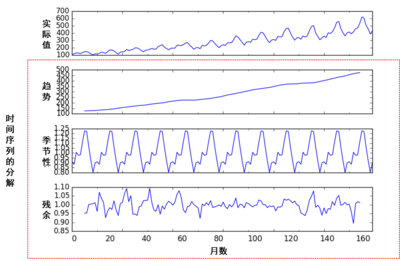
图 1:时间序列的分解
出处:How to Decompose Time Series Data into Trend and Seasonality,作者Jason Brownlee,machinelearningmastery.com。
在实践中,符合季节性带趋势的情况很多,比如城市的用电量,商用车的销量,甚至治疗糖尿病的药的销量,都呈现出趋势加季节性的特点。就拿商用车来说,某公司的商用车销量呈现明显的上升趋势,一直到2015年达到顶峰;每年的销量有季节性,比如3月份一般是销售旺季----春节过完了,大家对新的一年都是信心满满,纷纷添置商用车这样的固定资产加油干;然后需求就缓下来,在六七月达到谷底后,就开始反弹,在9月份又达到一个高点。
时间序列的可分解性,有着极其重要的实践意义。它让我们从貌似纷繁复杂的世界里,提炼出我们能够理解的,即趋势、季节性等有重复性、延续性的成分,把未知留给那些随机变动的部分。经过分解,我们会发现,大部分变动的其实是可知的,也就是数据可以解释的;未知的只是很小一部分,需要数据外的判断。
那些未知的随机变动中,有相当一部分是管理行为导入的变动,不是客户就是我们自己,或者是竞争对手的管理行为,比如促销、活动、降价等,这些其实有一定的可预见性,如果找到那些导入此类变动,或者熟悉竞品、客户行为的职能,比如市场、销售、门店经理,让他们及早帮助判断的话。剔除这些管理导入的变动,剩下的才是真正的随机变动,需要交给数理统计,设置安全库存来应对;或者依靠供应链执行,通过赶工加急来对付。
就这样,我们把需求分解成了三大块:(1)历史数据完全可以揭示的趋势、季节性变动,只要我们分析历史数据,即能很好预知,这就是"从数据开始";(2)管理行为导入的变动,比如促销、活动、新品导入和老品下市,只要我们更好地对接市场、销售等职能,"由判断结束",即可大幅降低大错特错的概率;(3)数据没法解释,判断也没法预计的随机变动,我们要通过设置安全库存和供应链的执行来应对。
现在你知道,为什么需求预测主要是个计划行为:计划的数据分析不到位,没法把有规律的可知部分提炼出来,就把所有的变动都当做不可知,于是就不可避免地依赖销售"提需求",走上一条不归路。数据驱动的计划都没有能力分析数据,经验主义的销售、市场就更分析不了,企业在需求预测上就不得不"从判断开始,由判断结束",靠拍脑袋,在粗放管理的泥淖里打滚。
即便是随机部分,也不是完全的不可知----小概率事件一旦发生了,就不再是小概率事件了。也就是说,凡是发生了的,其实都有其必然性。任何可预知的东西,比如趋势、季节性,最初也往往是以"随机"的面目出现。比如原来的需求挺稳定,业务开始增长时,增长部分是水平部分没法解释的,就被归到随机部分;业务继续增长,你会发现"随机"变动中,有了趋势的成分,变成了可以预测的。季节性变动也是。
我们的解决方案呢,一方面是尽快滚动预测,纳入最新的需求历史和职业判断;另一方面是选择、配置合适的模型,通过模型更好地"规律"化这些"随机"因素。
比如在简单指数平滑法中,我们可以通过调整平滑系数,决定把多大比例的"随机"变动当成规律性的变动----平滑系数越大,我们认为随机变动中的规律性比例就越高。在霍尔特法中,我们通过增加趋势的平滑系数,能更好、更快、更系统地把这些"随机"成分趋势化。而霍尔特-温特模型呢,则在霍特模型的基础上,增加了季节性参数,把那些"随机"成分中的季节性因素也给规律化了。
既然对历史需求可以自上而下地分解,那么对需求的预测呢,也可分别预测,自下而上地汇总。这也正是人们对付复杂预测问题的方法。比如对于趋势,我们可用霍尔特法来应对,分别预测水平和趋势两部分;而水平、趋势、季节性三者的组合,我们可用霍尔特-温特模型来应对,分别预测三部分后叠加。
相比霍尔特模型的双参数,霍尔特-温特模型增加了季节性参数,变成了三参数:水平部分对应的α平滑系数,趋势部分对应的β平滑系数,季节性部分对应的γ平滑系数。霍尔特-温特模型是个很好的模型,因为我们可通过合理设置三个平滑系数,来优化趋势加季节性的预测模型。
不过优点也是缺点:霍尔特-温特模型的公式相对复杂,优化起来更加困难,大部分的人应该没有能力,来熟练驾驶这三个参数----用不好的话,预测准确度可能反倒更低。想了好久,决定在此只是做个基本的介绍,点到为止,给感兴趣的读者开个头。如果你们有具体的案例,我们也可以一起研究,在本书的后续版本中补齐。
[1] 案例来自How to Decompose Time Series Data into Trend and Seasonality,作者Jason Brownlee,https://machinelearningmastery.com。
[2]Excel就可以帮助我们把时间序列分解为趋势和季节性,可以百度"运用Excel分解时间序列"。SPSS软件也有这功能,详情请百度,或参考"用spss进行时间序列分析"一文(https://www.cnblogs.com/114811yayi/p/5661817.html)。





评论