在需求预测上,层层报批是种很常见的做法。
案例企业是个乳制品企业,在全国有几十个片区,汇总到几个大区,最后汇总到总部。每个月做计划的时候,几十个销售经理滚动预测各自片区未来3个月的需求,分别提交给自己的大区总监;大区总监汇总、调整后,提交给总部的计划;总部计划汇总、调整后,驱动生产和采购执行。
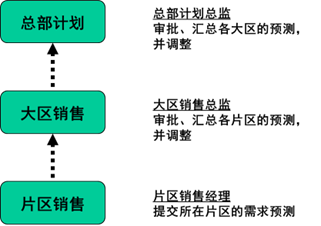
层层提需求,上下级、跨职能博弈,藏着掖着,信息不对称
这算不算"从数据开始,由判断结束"?当然不算。
首先,越往片区,数据分析能力越弱,预测的颗粒度越小,预测的准确度越低。片区的销售经理们学历普遍不高,有些人连Excel都不会用,你不能期望他们能做什么数据分析;整天做生意,也没多少时间做数据分析。所以,他们提交的预测,主要以经验判断为主,是"从判断开始,由判断结束"。而总部的计划呢,因为远离客户端,其实是没有判断的。这就陷入没有数据的职能提供数据,没有判断的职能做判断,错误的人在做正确的事,预测准确度注定不高。
其次,层层提需求,层层审批,其实是层层做承诺,注定充满博弈。比如,片区经理们知道,他们提的需求,可能成为后续绩效考核的依据,那就藏着掖着;大区总监们当然知道,下面提交的数据有水分,但究竟有多少却不知道,而他们提交给总部的时候,同样是藏着掖着;总部计划也是,藏着掖着做调整,然后给生产、采购。前端的需求职能这样做,时间长了,后端的供应职能肯定也开始博弈。于是,上下级、跨职能的层层博弈下,信息不对称,形成多重需求预测,加剧了部门、公司内部的"牛鞭效应"。
要知道,从数据开始,由判断结束的本质是消除信息不对称:计划分析历史数据,运用数据模型制定基准预测,拿出来放在桌面上;销售、市场、产品等职能提交活动、促销和新产品导入方案,以及其他可能显著改变需求的变量,评估对需求的影响,放在桌面上;信息对称下,数据和判断相结合,就得到准确度最高的错误的预测。这也是基于共识的预测。
【实践者问】一直以来,公司的计划模式为计划提出收集需求--业务提交--计划汇总--业务领导根据计划汇总的结果给出总数量调整意见--计划调整然后敲定。按此做出来的计划生产和采购总投诉不准,如何才能提高准确度?
【刘宝红答】这是典型的层层提需求,其实也是计划职能薄弱,退化成打杂职能的表现,只能做点事数据搜集工作。那么多的业务人员,预测颗粒度那么小,数据分析能力那么弱,其预测准确度可想而知;那么多的烂数字,加到一起会不会互相抵消,东边不亮西边亮?往往不会,因为业务人员受同样的外界因素影响,比如短缺时大家都拔高预测,过剩时大家都降低预测,都注定预测准确度不高。
摘自《供应链的三道防线:需求预测、库存计划、供应链执行》第2版,刘宝红著。





评论