案例企业有着强大的粉丝团体,传统上走的是粉丝经济,虽然在向品牌经济过渡,但粉丝经济还是营收的重要构成。为了最大化粉丝收益,案例企业就不断推出新品,基本上是每周都推出一款新品。
该企业走的是中高端、差异化路线,品种多,批量小,首批推出一般也就几百到几千件。多种少量的挑战是预测很难做,要么过剩,要么短缺,在案例企业得到充分体现。
这不,有一款新品在4月份推出,几天卖完了三四千件,紧赶慢赶地返单,等第二批到货时,都已经6月份了,爆款带来的"热气"也快消散完了,又得重新预热。有爆款,自然就有滞销。比如有个产品,为了走量降成本,首批进货几千件,结果只卖掉几百件,投入巨大的资源促销也不管用,一旦过季,就只能等到第二年,呆滞风险就很高。
需求不确定性很高,首批订货风险大,需求预测的压力就很大。预测风险高,没人愿意承担,最终就只能是老板拍板。
老板做预测,自然有老板做预测的原因:他是最有经验、最有权威的那个人,而且最能承担预测失败的后果。但是,随着业务连续翻番,新产品越来越多,事情越来越多,老板越来越忙,离消费者和一线运营越来越远,能花在需求预测上的时间越来越少,很多时候就只能拍脑袋做预测,其弊端也就越来越明显。"希望大boss理解科学的办法和拍脑袋的差别,特别是一个或者是二个人的拍脑袋",案例企业的一位员工在问卷调查中如是说。
老板当然理解科学决策和拍脑袋的差别。天底下没有一个老板会说,科学决策糟糕,让我来拍脑袋。但问题是,当我们缺乏有效的机制,没法有效整合跨职能的智慧和信息,一帮人没法有效决策的时候,老板不靠自己拍脑袋,还能靠什么?所以,这里的问题不是改变老板的行为,而是提高集体决策的能力,找到更好的方法论来整理数据,整合判断,做出更准确的预测来。
这方法论就是德尔菲专家决策法。当数据非常有限,未知因素非常多,决策的不确定性非常高的时候,德尔菲法是一种相当不错的选择。最早在二战后期,美国空军就用这种方法,召集相关领域的专家们,判断新技术的走向,指导新武器的研发。在上世纪50年代,兰德公司进一步优化这套方法论,比如预测使用核武的可能后果[1]。这套方法论有多种变种,但关键都差不多:专家,匿名,多轮反馈和修正,直到最后达成共识,或者达到预先设定的门槛,比如重复了多少轮,如图 1。
专家:这是早期决策,数据非常有限,那就只能靠判断。谁有判断?专家。但是,越是专家,其接触面反倒越窄----要想精通一个领域,就只能选择一点深挖。而新产品、新技术的开发涉及面很广,任何一个专家都没法全面覆盖,那就请多方面的专家来判断,以增加预测的准确度。
匿名:这是为了避免权威、头衔、职位、个性、名声等的影响,以避免强势职能影响弱势职能、强势人物影响弱势人物。你知道,老板坐在那里,不管在多民主的企业,大家都会自觉不自觉地跟着老板的思路走。强势职能在场,他们的胳膊最粗,拳头最大,八成最后也是他们说了算。名人光环就更不用说了。在新品预测上,匿名就是汇总预测数据时,略去头衔、姓名,有时候甚至是职能,这样也让大家更加放心、独立地做出各自的判断。
背靠背:这是为进一步减轻了职能与职能、人与人之间的博弈。大家坐在一起讨论,各抒己见的过程其实是个博弈的过程:每个人都代表自己的职能,他讲什么话,做出什么样的判断,很大程度上取决于别的职能、别的人采取什么立场,而且习惯性地藏着掖着,比如不愿意首先发言----发言就如谈判,谁先亮牌,谁就在博弈中处于被动。大家背靠背地做出判断,由专人搜集整理,有助于降低互相影响、互相博弈,让大家更可能以专家身份做出客观判断。
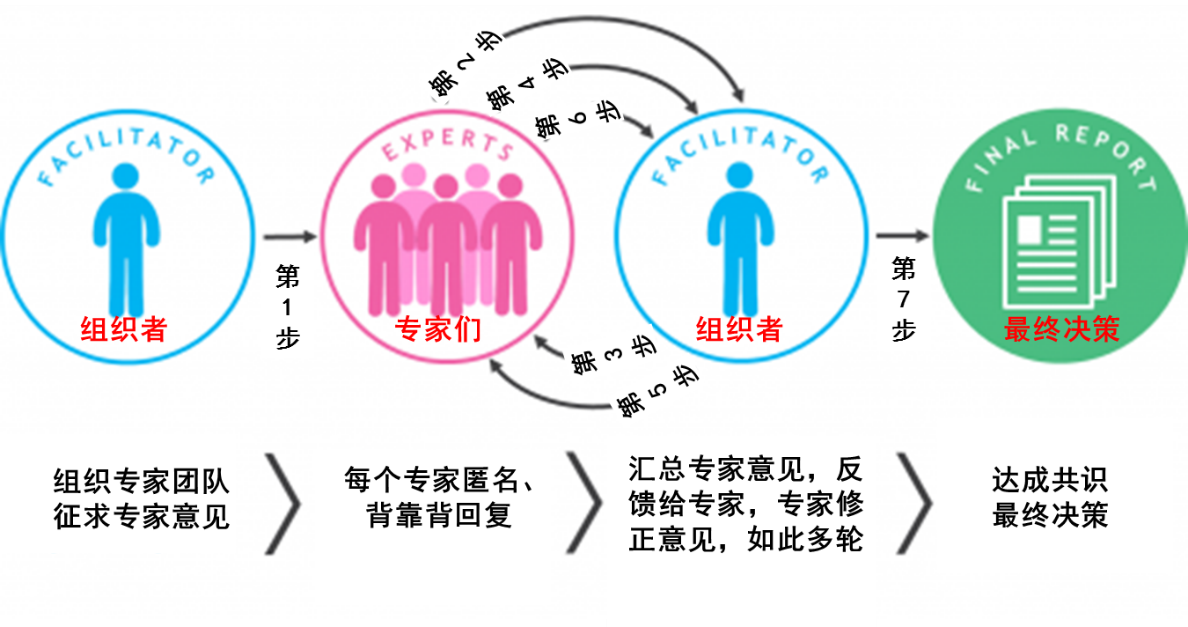 图 1:德尔菲专家决策法示意图
图 1:德尔菲专家决策法示意图
来源:Delphi Method, Dr. Phil Davidson, University of Phoenix, https://research.phoenix.edu/content/research-methodology-group/delphi-method
德尔菲专家决策法还有个重要特点,就是多轮循环:每个专家匿名、背靠背做出判断,由专人搜集整理汇总,提供给全体成员,成为下一轮判断的基础;在上轮信息的基础上,专家们调整自己的决策,一般会更加一致,表现在预测上,就是预测值的标准差更小、离散度更小;如此再三,最终达成一定程度的共识,比如以平均值或者中位数作为最终的预测[2]。
专家判断法本质并不难理解:"三个臭皮匠,赛过诸葛亮",这道理大家都懂;真正的挑战在以下几个方面,处理不好,会导致专家判断法流于形式,达不到期望的效果,而最终又回到老板做计划、老板拍脑袋的老路上来。
其一,选择了错误的专家。就拿需求预测来说,专家的定义是在某个方面深入了解这个产品。比如设计师熟悉这个产品是针对大众还是小众,产品经理在熟悉这个产品与别的产品的关系(替代还是互补、独立),电商经理熟悉促销计划和消费者的嗜好,采购经理熟悉成本构成和最小起订量----这些信息大都在具体的产品层面,能显著影响产品的需求。但在实践中,人们往往在专业层面确定专家,那专家团队就变成了首席技术官、营销总监、产品总监等。这些人是各自领域的专家没错(至少名义上没错),但往往并不是具体产品的专家,对具体产品所知有限,并不是做出产品预测的最佳人选;他们职位高,责任重,沉湎于各种事务,往往也没有足够的精力投入到具体的新品预测中,对具体产品的判断往往低于平均水平,反倒拉低了整体的判断能力,也降低了决策效率[3]。
其二,把专家判断等同于专家拍脑袋。专家判断还是得遵循"从数据开始,由判断结束"的决策流程,只不过数据比较少,更加不结构化而已。对于产品层面的专家,他们聚焦自己的领域,往往缺乏整体层面的信息。比如这个产品跟现有产品的关系,是竞争还是互补?现有相关产品的销量如何?以前类似产品的需求预测、实际销量如何?对于这个新品,企业的销量目标是多少?我们不能简单地把销售目标当成需求预测,但前者的确是后者的一大考量因素。这些信息需要组织者统一整理,提供给每个领域的专家,以尽量缩短他们的学习曲线,减少循环的次数,尽快达成共识。否则,德尔菲专家判断法无非就是把一个人拍脑袋变成多个人拍脑袋,没有改变拍脑袋的本质,也没法系统提高决策的质量。
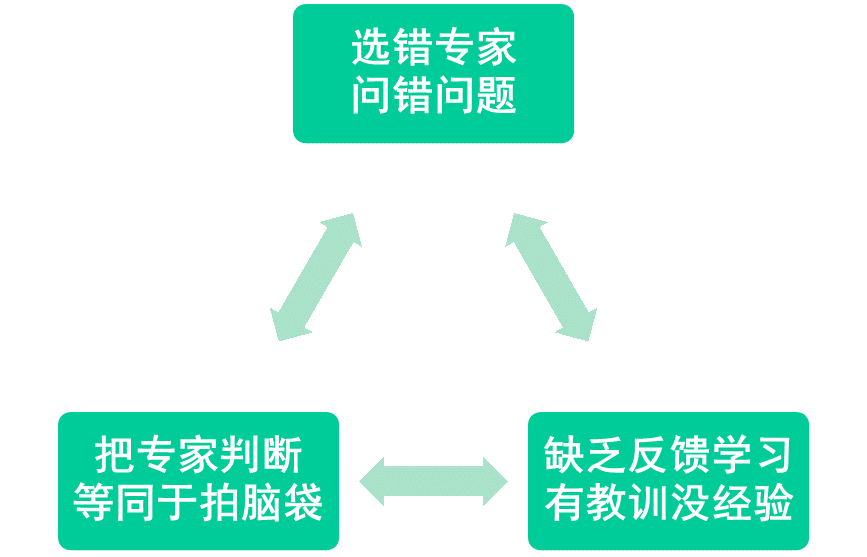
图 2:德尔菲法失败的几个原因
其三,缺乏反馈机制,有教训没经验,没法持续提高决策质量。专家判断法很容易被当成一锤子买卖,但其实不是:我们一直在导入新产品,一锤子买卖经常做,就变成了经常行为,需要不断改进,提高新品预测的准确度。这里的关键是形成闭环反馈机制。新品上市了,有了销量,我们要跟需求预测对比,跟每个具体专家的预测比,看他们对是对在何处,错又错在哪里;某个专家一直虚高,为什么?另一位专家一直虚低,为什么?这是组织者的一项重要任务:他们需要把这些数据收集起来,建成数据库,真正形成集体智慧和经验,提高以后新品预测的准确度。但现实中,很多公司把专家判断法做成一锤子买卖,没有反馈和总结,容易形成有教训,没经验,随意性大,准确度低,最后就又回到老板拍脑袋,或者强势职能说了算的状态。
对于案例企业,我们确定一个具体的产品来做试点,以导入德尔菲专家判断法。该产品正好处于开发后期,需要确定首批订货量。该产品也是案例企业重点开发对象,能够得到专家们(跨职能团队)的重视。
找好了产品,我们围绕这个产品,进一步确定了该新品预测的的专家团队,包括以下职位:
- 产品经理。该企业采取集成产品开发(IPD),由产品经理担任项目经理,对产品全权负责,在新品上市中扮演关键角色,包括新品的需求预测。
- 设计师。该职位具体负责该产品的设计,熟悉产品的定位,比如是基础款,还是大众款,以及特定设计对需求的影响,比如颜色、辅料的选择等。
- 门店经理。该职位负责主要网店的销售,熟悉消费者的需求模式,有能力对不同产品做出横向比较,也熟悉上新促销计划等。
- 数据工程师。实际上的计划经理。该职位负责数据化,熟悉各种产品的需求历史,能从历史数据的基础上帮助需求预测。
- 研发负责人。研发负责人特别熟悉产品,了解用户。她在微信群、QQ等社区小组里非常活跃,熟悉用户需求,对用户认知挺多。
- 销售负责人。虽然直接参加新产品开发较少,但经验丰富,熟悉客服团队的反馈,能帮助做多个产品的横向比较。
- 供应链负责人。熟悉产品的成本、最小起订量、供应商的阶梯报价等。也熟悉关键原材料的共用性和货期,能够从供应端帮助需求预测。
- 总经理。创始人不可替代,尤其在还处于小而美但快速发展阶段的案例企业。总经理深度介入产品开发、企业运营、定价决策等,经验丰富,历来在新品的需求预测上扮演关键角色。
确定了产品和专家团队后,组织者把专家团队召集到一起,解释德尔菲专家判断法,展示产品的样品,启动专家团队"从数据开始,由判断结束"的新品预测流程。
首先,我们究竟要专家团队预测什么?在一个微信群看到这幅漫画,医生们在上街罢工游行,但举起的牌子上,却歪歪扭扭地写着处方一样的字,谁也看不清楚他们的诉求是什么。你知道,这是在戏谑那些开处方如同天书的医生[4]。放在新品导入的专家决策中,我们究竟要这些专家预测什么?案例企业说,产品上新,预测首批订单量呗。这不清楚,有两个问题:

图 3:诉求不清,是另一种垃圾进,垃圾出
其一,预测有数量和时间两个维度,首批订单量只有数量,没有时间----这首批制造的产品,究竟预计在多少时间售完?我们把时间的口子开着,专家成员就得做出自己的假定;对时间的假定不同,专家成员的预测肯定不同,缺乏一致性,没有可比性,成了垃圾进,垃圾出。
其二,"首批订单量"问的是供应,即向供应商下多少订单;而专家团队中,大部分人最熟悉的却是需求,没法针对供应做出很好的判断:首批究竟生产多少货,还受产能、采购周期、规模效益等影响,比如产能有限,可能得降低订单量;供应周期越长,订单量就越大;最小起订量越高,首批订单量可能越大。
跟案例企业讨论以后,我们决定问专家团队两个问题:(1)上新30天内,您认为可能销售多少?( 2)除此之外,您认为还可备多少产品的原材料(长周期物料),这样一旦需要补单的话,我们可以快速反单?我们特别提醒,希望这些原材料能在3到6个月内消耗完毕,以期控制原材料的呆滞风险。
问题1其实问的是上新30天的需求预测,有时间、有数量,限定很清楚。在上新阶段,专家团队里的销售、设计、产品管理等职能深度介入,对过去的新品有一定的经验,对下一个新品能够做出一定的预判。
问题2问的其实是第二、第三个月的预测。案例公司的整个供应链周期大致是3个月:原材料采购1个月,加工成半成品1个月,加工成成品1个月。由于上新的不确定性非常高,案例企业通常采取长周期原材料统一采购,以获取一定的规模效益,但只把部分加工成成品,以控制成品的库存风险。上新一开始,第一天的销量就很有参考价值,决定是否要赶快把剩余的材料加工成品(这点后文还会讲到)。
我们理解,第一个问题相对更直观,应该能得到不错的判断;第二个问题相对更难做判断,专家团队需要更好地理解整个供应周期,以期提高对长周期物料的预测、管理(在具体案例中发现,专家们对第二个问题判断不是很好)。
确定了要问的具体问题,下一步是哪些信息是已知的,可以统一提供给专家团队,以缩短学习曲线和提高决策质量?要知道,专家决策并不是拍脑袋;他们是在以往经验的基础上做判断。而以往的经验呢,其实很多已经凝聚在数据里,比如销量,我们可以汇总这样的数据,统一给专家团队。这对那些不经常跟数据打交道的职能,比如设计和产品管理,特别有帮助。否则,他们就会纯粹拍脑袋。
在案例中,我们决定提供两类的信息:(1)类似产品的信息,比如不同时段的销量;(2)该产品的特定信息,比如产品的定位,原材料的最小起订量,供应商的阶梯报价。
类似产品信息:去年有6个类似产品,分别是什么时候上市,首批生产了多少,上架30天卖掉多少,首月售罄率是多少,3个月、6个月累计卖掉多少,这让专家团队有了更多的横向比较的信息(如图 4)。组织者原来还提供前年的类似产品,但有两个问题:(1)时间较久了,上新期间的销售数据不全;(2)两年的产品太多了,容易造成信息过载,反倒影响专家成员有效判断。组织者也想提供每个产品的四象限分类(产量的高低与销量的高低),以及退货率等,同样有信息过载的问题,就一并拿掉。

图 4:可参照产品的历史销量(案例企业机密信息遮盖掉了)
该产品的信息:产品定位是高价位、中价位还是基础款(走量的)?跟已有产品的关系是互补,蚕食,还是独立?这些都会影响产品的预测。此外,预测还需要采购相关的数据,比如主要材料的最小起订量,供应商的阶梯报价,有无特殊工艺,比如染色、表面处理等,以及相应的附加费用(跟最低起订量有关)。
组织者把关键的背景信息准备好,编辑成一页A4纸大小,就召集专家会议,解释了德尔菲专家判断法的方法论,展示产品样品,把基本的背景信息分发给大家,就开始多轮的预测过程。
第一轮,每一位专家回到自己的办公间,分析已有的数据,搜集更多的信息,独立、背靠背地做出判断,扫描二维码,通过问卷星(www.wjx.com)在线填写以下信息(如图 5):
(1)新品预测:上新30天内,销量预测是多少?还应该备多少原材料的库存;(2)所依据的理由;(3)进一步完善该方法论的建议,比如哪些有用的信息没有被提供,哪些合适的人没有被邀请到专家团队等。
在问卷最后,我们要求每位专家填写自己的姓名等信息。这主要是为督促专家们认真完成任务,也帮助组织者跟踪各个专家的判断结果,以期循环改进。在这里,组织者明确说明,填写的结果会以匿名的方式反馈给专家团队,以便让专家们没有后顾之忧,做出最好的判断。
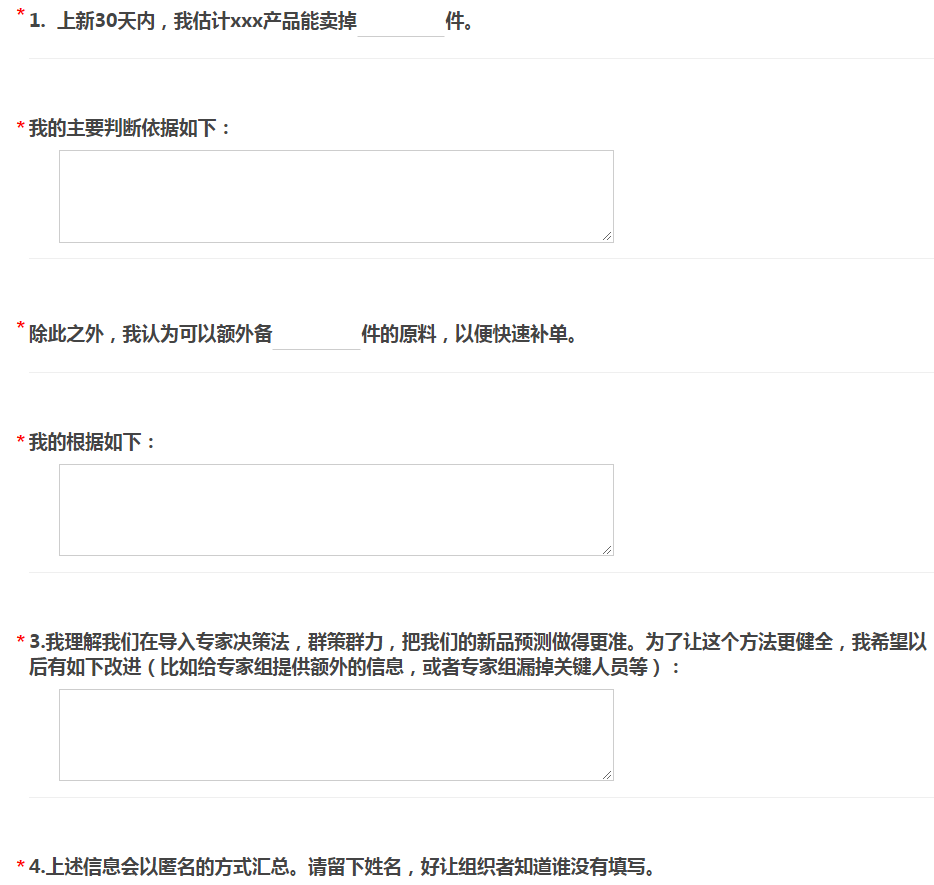
图 5:首轮判断的问卷设计
组织者汇总第一轮的结果,比如8个跨职能专家中,每个人做的预测分别是多少,其理由是什么,再附加额外可以提供的信息(根据第一轮的专家反馈),统一分发给专家团队。召集专家团队简单会议,确保大家理解第一轮的结果。注意,讨论不是让大家判断谁对谁错,应该怎么办。否则,强势职能可能影响弱势职能,强势人物可能影响弱势人物,从而影响了第二轮预测的客观性。
第二轮的方法论与第一轮一样,每个专家成员独立、背靠背地决定,是否修改自己在上一轮的预测结果,并写明理由。
组织者汇总第二轮的结果。如果第二轮的结果分歧还比较大,就进入第三轮。希望最多三轮,专家团队在该新品的预测上,能够达成相当的共识,组织者最终以取平均值或者中位数的方法,决定最终的新品预测。
对于上新30天的销量预测,两轮预测后,7位专家(其中一位专家度假,只做了第一轮,就剔除了)的结果显著趋同,表现在标准差和离散度上,就是这两个数值明显降低----离散度从第一轮的xxx降为xxx,标准差从xxx降为xxx,如图 6所示。
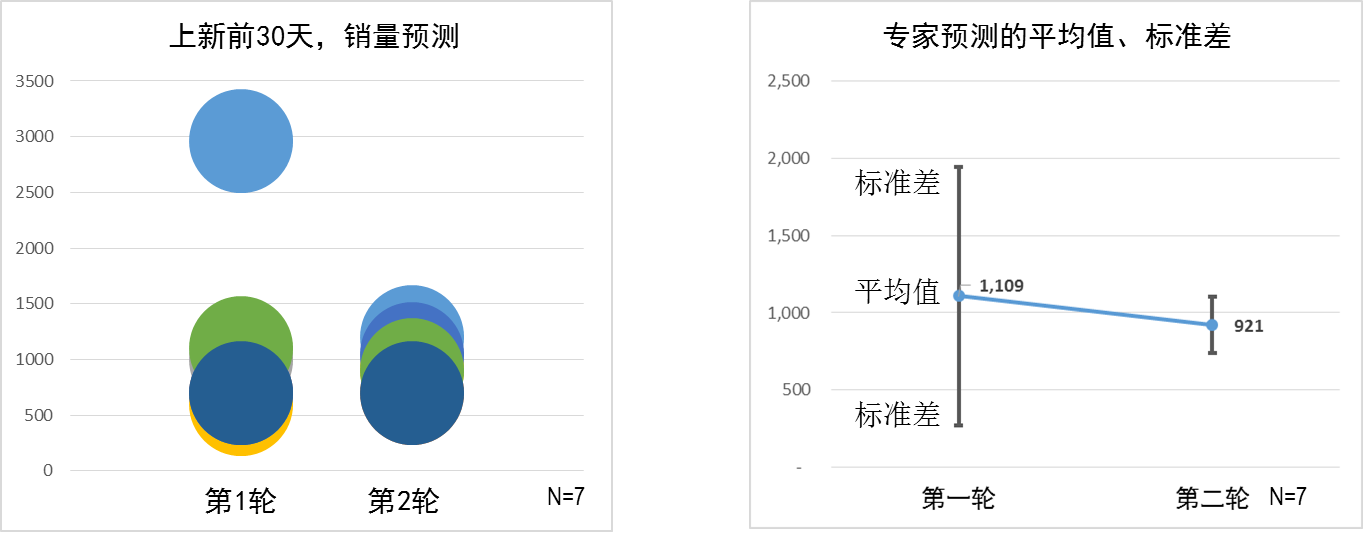 图 6:两轮预测后,专家预测值的离散度大幅下降,预测值更加趋同
图 6:两轮预测后,专家预测值的离散度大幅下降,预测值更加趋同
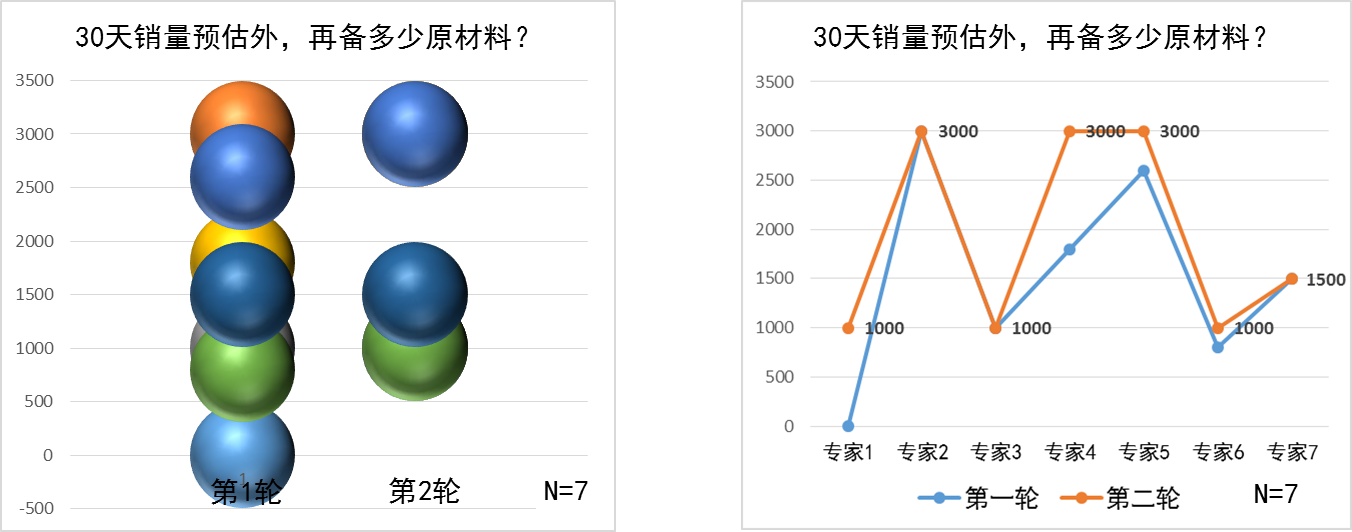
但是,对于额外备料的预测,两轮专家判断后,预测的离散度却依旧很大。
如图 7所示,虽然左边的图片看上去更加"趋同"了,但这有误导:第一轮的预测是从0到3000的很多值,第二轮则主要集中在1000和3000上----3位专家预测1000,另3位预测3000。这不应该是巧合,看上去更像相当一部分人心里没底,就"扎堆",看第一轮预测中哪个人的理由充分,就随那个人了:首轮预测3000的那位说,基于成本和此产品的差异化设计,该产品的目标应该是基础款、高销量;而首轮预测1000的那位则说,该款式设计上与别的"撞色","在夏天不讨喜,预计只能在春秋两季去推",而且3到5月有多款类似产品上线----该款明显是低销量,没后劲。这两个理由看上去都很充分,大家就跟风变成了两派。不过1000跟3000的差距可太大了,所以说专家们在这个问题上并没有达成一致。
当然,这也反映了在该产品的定位上,案例企业还没有达成共识。
作为案例设计者,我认为我们问了错误的问题:专家成员中的产品经理、设计师、研发负责人等等主要经验在上新前后,至于上新完成,补单该补多少,他们其实没有经验,自然就没法做出高质量的判断。我的建议呢,就是以后不让专家组预测后续备料,而直接由供应链根据30天销量的预测,来预估后续两个月的需求----我们后面会讲到,上新期间的销量和后续正常销量关联度很高。
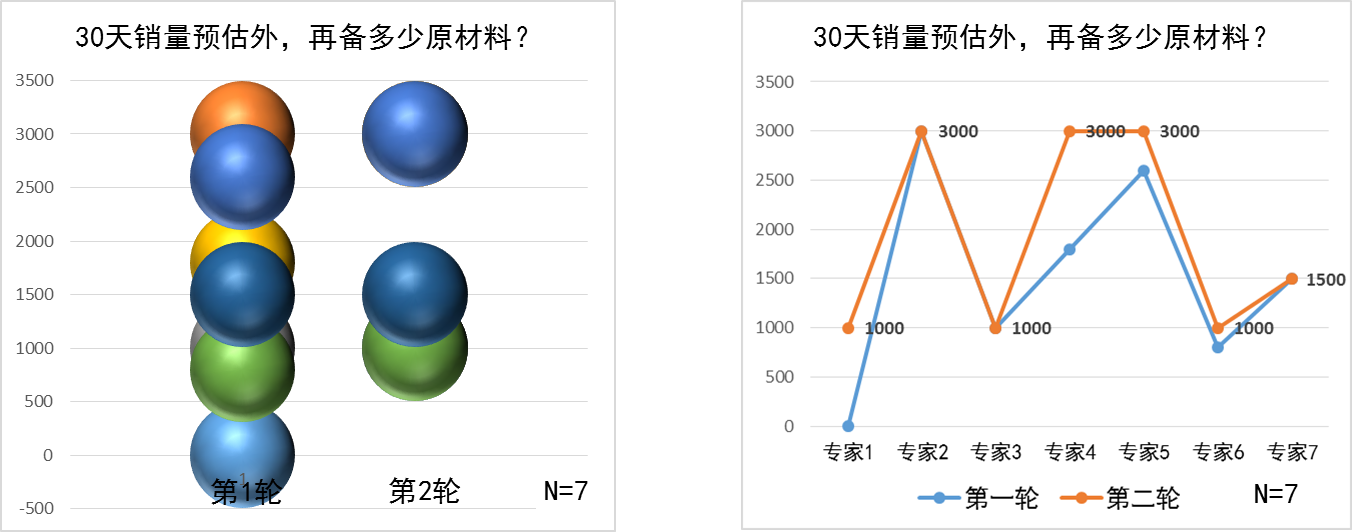
图 7:两轮预测后,额外备料的预测还是差异很大
这个案例还没有结束。作为一个实习案例,等到产品的真实销售数据出来后,我们还要进一步总结、分析,看预测的准确度如何,并总结经验提高。比如奖励最准确的专家,小组分享成功经验,总结失败教训等,让更多的员工参与学习,比如产品经理们就应该深度介入,每个人都应该熟悉这套方法论。这才算闭环完成。
此外,作为方法论的一部分,企业还得决定(1)什么样的产品适合于德尔菲法?(2)由哪个职能来负责、维护这一方法论,以及背后的流程?
德尔菲法需要跨职能参与,前后多轮,外加基本信息的准备和多轮数据分析,对资源的要求较多,属于"重武器",所以不能滥用。企业得定义适当的产品,比如不确定性较大,新的功能较多,类似产品较少等。
同理,德尔菲法需要责任职能来维护。总体而言,这是个决策流程,是需求计划的一部分,可以由计划职能来维护。当然, 在很多企业,特别是小而美的企业,新品的需求计划往往是产品经理的责任,这个流程也可以由产品管理来负责。但问题是产品管理相对分散,比如有多个产品经理,有些产品之间的搭接度不高,难以找到唯一的对接口,最佳实践的难以固化、传播。计划职能呢,虽然天然是集中的,但往往影响有限,难以有效推动跨职能协作。或许可以这样尝试:德尔菲法作为新产品集成开发的一部分(IPD),由产品管理整体负责,但由计划职能负责组织、执行。这跟产品经理负责整个产品的开发,而由设计负责具体的设计工作是一个道理。
[1] Avella, J. R. (2016). Delphi panels: Research design, procedures, advantages, and challenges. International
Journal of Doctoral Studies, 11, 305-321. Retrieved from http://www.informingscience.org/Publications/3561
[2] 之所以用中位数,是为了避免极端值对平均数的影响。比如我跟盖茨的平均财富是490亿美金,但你知道那都是盖茨的钱。这也是为减少博弈,比如某个职能有意虚高。当然,当数据的离散度较小时,平均值应该比中位数更接近真相,在数理统计上更有意义。
[3] 我问一个企业,为什么返单的周期长?答曰主要是决策慢和物料采购周期长。长周期物料容易理解。决策慢,当然是慢在那些决策者:越是职位高的人,越缺乏产品层面的信息,要他们做产品层面的决策,比如需求预测,他们当然不放心,于是拖延症就占了上风,导致迟迟做不出预测;预测错了,也没法尽快纠偏。
[4] 我在英国的《今日电讯》(The Telegraphs)上看到相关的医生罢工,以及这位愤怒的医生举牌子的另一幅照片,上面倒是写得很清楚,就知道微信群里的这幅图是PS过的。原文:Doctors' strike: the NHS exists to serve patients, not keep doctors happy,作者JAMES KIRKUP,www.telegraph.co.uk。





{kind=link}
非常好的分享。
现在中国企业发展非常快,但是的确缺少科学化的决策流程,更多的依靠领导的拍板,还有经验,科学决策的实施,依靠科学的流程,和大量的数据分析。一个靠经验,靠权威来决策的企业,即便发展在快,也是短期的,最终不可能击败那些依靠科学体系化的企业。而这将会是中国企业未来一个很重要的课题。