有个代理商,库存和交付一直是个问题:短缺时有发生,而手头的整体库存却居高不下。他们想从需求预测和库存计划着手,对付这个问题。他们的计划主管首先导出几个产品的历史销量,做了折线图想从中发现规律,却看不出什么门道。问我该怎么办,我就把数据要过来----谈到具体的计划问题,不看数据就无异于瞎谈。
历史数据过来了,一眼就发现不对劲儿:一年是52周(有时候零头会成为第53周),为什么这数据只有50周?剩余的两周到哪里去了?问他们的计划主管,她也不知道,因为她拿到的是二手数据。这就是计划要解决的首要问题:数据的准确性。
对于计划人员来说,我们对任何数据都要心怀戒备,尤其是汇总整合后的数据:一定要从最基本的数据,即原始的客户订单开始。
对于这个案例,我就索取原始的客户订单数据,比如订单是什么时候接到的,要什么货,要多少,什么时候要,什么时候发货等。案例公司说,订单接到日期和发货日期在不同的系统里,很难凑到一起。那好,那就给我发货的数据:凡是个企业都会有发货数据,不然怎么跟客户收钱呢?但作为计划人员,你得意识到用发货数据做计划有风险,这里举几个例子。
第一, 短缺未发货的订单没有进入需求历史。比如客户上月要100个,你如果有货的话上月就发了,这就形成上月的需求,在需求历史中出现,指导未来的预测;如果没货,要到3个月以后才发货,意味着如果依赖发货历史来计划的话,你会低估需求,在计划上滞后。这在业务暴增,比如出现爆款而大面积短缺时就更糟糕。解决方案呢,就是按照客户的需求日期来识别需求。比如客户说3月7日要100个,那100个就算作该日的需求,不管何日发货。
第二, 需求可能被匹配到错误的地方。比如这个客户默认的是由仓库A来支持,A仓没货,于是从B仓发货。如果按照发货历史的话,这需求就算到B仓的头上,导致以后B仓过量计划,而A仓则计划不足。解决方案呢,就是在信息系统里提取数据时,不管实际是从哪里发送的,需求都匹配到默认的发货仓。
第三, 有些企业是每天接订单,但每周或几天集中在一起发货,比如每周五发这周收到的订单。把发货历史当做需求时,你会发现周一到周四的"需求"是0,而周五的"需求"一大堆,这人为增加了需求的变动性,错误地导致增加安全库存来应对。
在有些管理粗放的企业,订单数据里没有"客户需求日期"这一项。那好,就用接到订单的日期,默认客户是随订随要,或者按照约定的交期来算。但这也有风险,比如客户一次给一个大订单,分批要货的话,我们会高估需求的变动性,从而可能增加了不必要的安全库存来应对。
解决方案呢,就是按照每次的客户需求日期来归置数据,这要求接单时跟客户确认。比如说,客户3月1日下了个大订单,总共要100个,分解为3月8日30个,15日50个,22日20个。那客服在接单的时候,就要在系统里把该订单拆分成三行,注明这三个需求日期,以及相对应的需求量。这是基本数据,在接收订单的时候就得搜集。
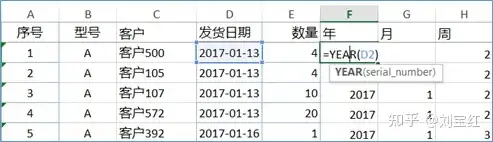
再回到这个案例。我拿到了最原始的发货数据,不完美,但也只能将就。这是逐日的流水账。为了便于进一步的分析,我先把数据按照年、月、周来切分。对于具体的日期,Excel中有个函数Year( )就可以求出对应的年,month( )可以求出对应的月,weeknum( )可以求出对应的周。我把这些公式在Excel里展示出来(见表 1),因为我发现很多人不熟悉这些基本的公式,经常花了很多时间在手工分类数据。
表1:Excel中计算年、月、周的函数
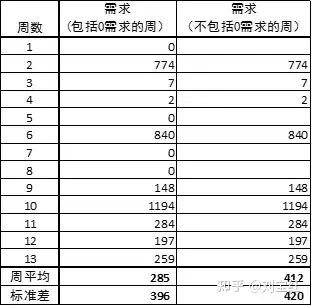
然后做个透视表,把数据按月、按周来汇总。这时候要注意,某一时段没有需求的时候,相应的时段在透视表里就不出现,或者出现但当做空格。在计算平均值、标准差等参数时,要把相应时段的需求设为零,否则会误导。比如在表 2中的例子中,过去13周中有4周的需求为零,正确的做法是把这些周设为0;否则,Excel会把它们当做空格,在计算时排除在外,把本来13个数据点当成9个,计算出的周平均和标准差就大不一样。
表2:在Excel中,空格与零不一样
这些看上去很琐碎,但魔鬼藏在细节中,这都是为了提高数据的准确性,避免垃圾进、垃圾出。过去十几年里,我手把手辅导过几十名计划人员,见过的基本数据问题真是数不胜数,尤其是在新兴企业,或者管理粗放的企业。数据不好,分析自然好不到哪里去,就如英语中有句话说得好:Your analysis is only as good as your data。
在这个案例中,案例公司给我一个产品的A、B两个型号做分析。这就引发另一个重要概念:产品的替代关系。比如B是新型号,要替代A的话,那么,A的需求历史要归到B上去。如果A和B能够互相替代的话,那就更复杂。比如客户要的是A,但因为手头没货,我们给的是B,那按照发货历史的话,这成了B的需求历史,而实际应该匹配到型号A上去。否则,我们会低估A的预测,而高估B的需求。
类似的还有客户替代:原来的客户甲,后来被客户乙并购了;或者原来这个地区的经销商是A,现在换成了B,前者的需求历史都要并入到后者。供货点替代也是:原来这客户由仓库A供应,后来改为仓库B;或者说原来的A仓关闭了,跟B仓合并,那相应的需求历史要并入B仓。
还有,同一客户,可能有多个收货地址,以及相应的编码。那么这些地址对应的编码呢,都得归并到同一客户编码,确保相应的需求都归到这个客户上。
在这两个型号的需求历史中,我发现有些需求是负数,那意味着退货。这是个传统的代理商,这两个型号的退货比例为4%;而在电商环境,这一比例可能高得多。比如有个做服装的电商,有些款式的整体退货率高达60%。我们这里要解决的问题是,退货后,从计划的角度怎么办。
分两种情况:如果退货可以再销售,那就抵消需求历史,降低收到退货时的需求(而不是接到订单时的需求----接到订单时,我们不知道是否会退货,还得按照正常需求来计划);如果退货没法重新销售,那就不能抵消需求历史。在这个案例中,退货还可再销售,那就抵消收到退货时的需求历史。
再就是促销。如果三天两头做促销,这就如小贩每天都在吆喝做生意,店里的小姑娘每天都在让行人进去看看,对整体销量的影响不大,那这种促销其实有一定重复性,可以算作需求历史----这不完美,但我们在分析需求历史的时候,往往很难把这样的促销识别出来。但是,对于618、双11、黑色星期五这样的大节,促销产生的需求是不可重复的,需要在需求历史中剔除。当然,上个双11的促销对做下个双11或许会有借鉴意义,但你不能不加区分地用11月份的销量,来预测12月的需求。
那如何识别促销数据?售价可帮助判断促销(比如打折)。相关的活动也是,比如团购。还有日期----你知道,6月18日是六一八,11月11日是双十一,12月12日是双十二。要注意的是,促销影响的不光是节日那天,前后多天也可能受到影响。我分析一个电商的数据(如图 1),发现双十一开始前两周,需求就显著下降----消费者开始观望,等着过节打折;而双十一结束后的一周,需求也明显降低----小姑娘们过节钱花光了,手已经被"剁"了,节后就自然不能再"败家"了。
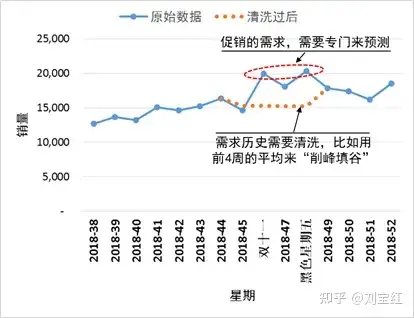
图 1:电商节日促销数据的"削峰填谷"
再比如美国的黑色星期五(感恩节的第二天),促销往往提前几天开始,节后延续到星期六、星期日。那几天购物中心是人山人海,车都没地方停。接下来的星期一呢,则是网购的高峰期:大家都上班了,人坐在办公室里,心却还没有回来,就用公司的时间来网购。法不责众,老板也只能睁一只眼闭一只眼。这段时间就是波峰,而前后一段时间则是波谷,其需求历史需要清洗。
那数据如何清洗呢?削峰填谷,即促销期间以及相邻的时段,用之前一段时间的平均需求来代替。至于说时段要有多长,这的取决于具体业务特点,跟移动平均法要用多长的历史数据道理类似。这就得到基准数据,然后用合适的预测模型,制定基准预测。对于后续的促销,则需要另行预测,叠加到基准预测上,就是最终的预测。比如基准预测是100个,预计促销能带来300个的额外需求,那需求预测就变成400个。这样,上帝的归上帝,凯撒的归凯撒,操作上就很清楚----重复性的需求由计划基于数据分析预测,非重复性的需求由销售、市场基于判断来制定。
有些计划软件有识别异常数据的能力,并剔除异常,拿相对正常的数据,比如之前一定时段的平均值,来替代异常数据。风险是,这种识别主要是基于数据分析,比如数据的变动性,把变动性超过一定幅度的当做"异常",自动剔除或用修正,导致得出错误的结论。比如让需求历史更加平缓,人为低估了需求的变动性,造成计划偏低,比如安全库存设置太低等。有些人拿到需求历史,会剔除最大、最小值,然后来预测未来的需求和设置安全库存,也有同样的风险。
所以,对于异常值,要非常小心。这方面,典型的例子就是南极上空的臭氧洞:多年来,由于氯氟烃的危害,南极上空的臭氧层一直在缩小,相关数据是监测到了,结果被软件当做不可靠的异常数据给自动剔除了,并被代以看起来更靠谱的数据。更具讽刺意味的是,美国宇航局也记录下了臭氧含量的变化,却又被当成操作人员笔误,又一个"数据清洗"造成的悲剧[1]。
再就是短缺造成的订单损失。这从需求历史中也往往能看得出。比如前几个月都是每月100,接下来两三个月都成了十几个,如果没有别的原因的话,那很可能就是短缺。在数据处理上,除了前面讲的,用前段时间的平均值来代替外,也可以用前段时间的需求作为基准,"预测"短缺几个月需求。这也是"削峰填谷",填上的是短缺或促销造成的需求损失。
断码是另一种情况。解决方案就是在断码前,看一下各种尺码、颜色的销售比例,然后根据后续没有断码的销量,来推算断码的销量,清洗好数据。
看到这里,相信很多人都开始头大。这只是最基本的数据清理工作。还有些杂七杂八的清洗,我们这里就不赘述,比如有些订单是按箱,有的是按个;有的是三联装,有的是六联装,我们得转换成统一单位。再比如有些客户丢失了,那我们要把他们的需求历史拿掉等。再比如一些一次性的大订单,或者产品生命周期结束时的管理决策,都会造成非重复性的需求,需要清洗。
相信很多人有同感:本来要解决的是预测模型和库存计划问题,但项目过了大半,却发现还在整理、清洗数据,而这只是漫长征程的开始。垃圾进,垃圾出,数据质量直接决定模型的效果,数据清洗是不可缺少的一环,通常占数据分析50%到80%的时间[2]。
网上常说的数据分析,主要对象是这几年流行的"大数据",而清洗工作也主要是通过计算机完成,比如检验数据的一致性,发现超出正常范围、逻辑上不合理或者相互矛盾的数据,供进一步核对和纠正;用样本均值、中位数或众数代替无效值和缺失值,删除特定样本,甚至删除整个变量等[3]。
公司大了,成千上万的产品,成百上千的客户,几十成百的库存点,这些零零碎碎的数据清洗工作,如果要人工来做,几无可能。在我的老东家,一个硅谷的高科技制造企业,数据清洗和整理工作由计算机做,每到周末,几台功力强大的服务器就马力全开,把基本数据从ERP中提取出来,做好清洗和整理工作,更新到计划部门的数据库里,支持下一周的需求预测和库存计划。
日常工作中,数据清洗和整理是计划人员的基本功,他们花在数据整理上的时间,往往要比花在数据分析上的多得多。这就如习武的人,大部分时间其实在站桩一样。这基本功无法替代:有些公司不愿意花时间清洗、整理数据,建好基本的数据库,就只好每次计划的时候人工清理,既重复劳动,又难以确保每次都做得一样好,后续的需求预测和库存计划就很难做到位。
还有些企业,计划职能的人手、能力严重不足,根本没有资源做数据清洗。比如有个公司,每年好几亿元的营收,共有700多个产品,上万个款式、颜色、尺寸(SKU),却只有一个计划专员。这位计划员做预测,完全是靠需求历史,对于618、双11、双12这样的节假日促销,都没有做任何数据清洗。你能想象的,就是一堆一堆的库存。
【实践者问】中心仓做预测的时候,需求历史取什么值?是前置库位的补货指令,还是前置库位最终卖给客户、消费者的销售数据?
【刘宝红答】卖给最终客户、消费者的销售数据。之所以这样,是为了避免信息不对称造成的"牛鞭效应"。比如说刚开始铺货时,渠道需要相当数量的库存,向中心仓的要货量会相当大,我们当然不能基于要货数据来预测后续的需求。再比如中心仓短缺时,前置库位争相拔高要货量,以期分配到更多的库存。如果用要货数据来预测,势必会高估需求,加剧"牛鞭效应"。
所以,对于中心仓,我们要用销售给最终的客户、消费者的需求数据,来做基准预测,力求总进与总出的平衡。
【实践者问】中心仓要以最终客户、消费者的销量为需求历史,我能够理解。但我还有个问题,最终客户有很多,需求有整合效应,整体需求的变动性较小;而前置库位的数量较少,针对中心仓的实际要货的变动量会更大。在中心仓,如果围绕最终销量的变动性,来设置安全库存的话,则有可能低估需求的变动性,导致给前置库位的有货率达不到目标。怎么办?
【刘宝红答】这是个很普遍的问题。我们的解决方案是需求预测仍旧用给最终客户的销量,但是安全库存的设置可以用前置库位的要货数据。这就是说,我们围绕实际的要货数据,计算其标准差,作为需求的变动性,来计算安全库存。安全库存的计算方法见第二章。





评论